Crawly介绍
Crawly是由AI数据提取领军企业Diffbot推出的智能网络爬虫工具,主打零代码、全自动的网页结构化数据提取。用户只需输入一个网站URL并留下邮箱,它便能像人类一样理解网页语义,自动遍历全站,精准识别并提取文章、产品、评论、图片等多类内容,输出为即用型JSON或CSV格式。其核心优势在于不依赖脆弱的选择器,而是融合计算机视觉与自然语言处理技术,具备强鲁棒性,面对网站改版不易失效;同时支持实体识别、多语言处理和全站深度抓取,让非技术人员也能轻松获取高质量数据。
Crawly网站截图
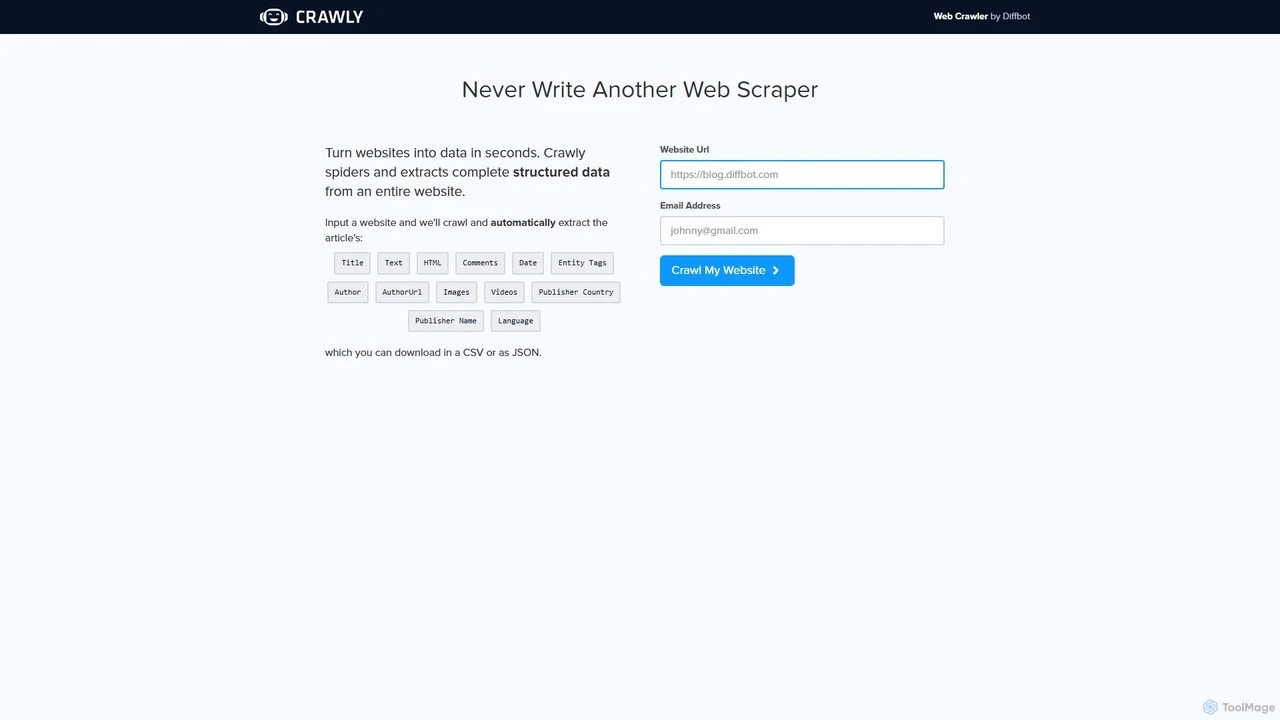
Crawly的主要功能
- AI驱动的全自动内容识别与提取
- 支持全站导航式抓取,不止单页
- 输出结构化JSON/CSV数据,开箱即用
- 自动识别人物、组织、地点等实体信息
- 无需编写代码或配置选择器
Crawly如何使用
- 访问Crawly官网,进入操作界面
- 在输入框中粘贴目标网站的完整URL
- 填写个人邮箱用于接收结果通知
- 点击“Crawl My Website”启动抓取
- 等待系统完成处理后下载结构化数据文件
Crawly的应用场景
- 市场研究:批量采集竞品产品信息与用户评价
- 潜在客户开发:从企业官网提取联系人及公司资料
- 内容聚合:跨站点抓取新闻、博客构建定制资讯源
- 机器学习数据准备:生成高质量标注数据集用于模型训练
- 品牌舆情监控:实时抓取全网对品牌或高管的提及内容










