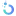xMem介绍
xMem是一款专为大语言模型(LLM)应用设计的混合内存编排器,致力于解决AI系统‘健忘’这一核心痛点,通过融合长期向量记忆与短期会话上下文,赋予AI持久、连贯的记忆能力。它智能编排RAG流程,自动从向量数据库(如Qdrant、ChromaDB)和实时会话中提取最相关上下文,无需手动调优即可提升响应准确性;内置知识图谱可视化功能,帮助开发者理解信息关联;开源友好,支持多种LLM、向量库和存储后端,兼顾灵活性与易用性,特别适合构建需跨会话记忆的智能助手与协驾类应用。
xMem网站截图
xMem的主要功能
- 混合内存系统:同时管理长期内存(向量数据库)与短期会话内存
- 自动化RAG编排:为每次LLM调用智能组装最优上下文
- 知识图谱可视化:实时呈现概念、事实与用户上下文间的关联关系
- 开源优先架构:兼容主流开源LLM(Llama、Mistral)及向量数据库
- 开箱即用的监控仪表板:提供内存分布、检索延迟、上下文相关性等关键指标
xMem如何使用
- 选择并配置所需组件:LLM提供商、向量数据库和会话存储后端
- 安装xMem SDK(支持TypeScript/JavaScript环境)
- 在代码中实例化xMem编排器,传入对应配置参数
- 使用orchestrator.query()方法替代直接调用LLM,由xMem自动处理上下文注入
- 通过内置仪表板监控内存使用、检索性能与知识图谱演化
xMem的应用场景
- 高级聊天机器人与虚拟助手:记住用户偏好、历史对话与个人信息,实现真正个性化交互
- AI协驾工具:持续维护项目进展、代码变更或团队讨论上下文,提供上下文感知的开发建议
- 智能客户支持系统:调取完整服务记录与过往交互,提供连贯、精准的售后响应
- 个性化知识管理系统:将新查询与用户既往研究路径、笔记和文档关联,增强知识发现深度
- 企业级RAG应用:在合规前提下,安全整合私有文档与动态业务数据,支撑决策辅助